IMHEX
Intro(ImHex | 十六进制编辑器) #
一个瑞士小孩哥使用 C++23 写的开源 十六进制编辑器,主要包括十六进制预览(Hex editor),单多字节数据编码(data inspector),基于节点的预处理器(data processor),书签列表(Bookmarks),一些其他内置工具,数据分析和图表可视统计,使用向导,在线商店,其中包括各路大神写的(类库,magic文件,编码集等)。
当然,最主要,也是最核心的就是下面需要单独介绍的 模式语言(暂且这么翻译)。
使用场景:
针对某个实例文件,结合模式语言,展现结构列表,可视化二进制数据。比如 分析 java 字节码, RIFF,ANI 文件格式分析,或者 分析 ext2 文件系统 等。
当前使用版本 v1.37.4
优点的话:开源,看不惯的话可以改。马上快 50K 的星标了,你想想。
缺点目前来说的话,就是,macosx 上面一不小心就闪退了,window上面保存项目文件,不知道死哪儿去了。数据处理器不能复用,另外模式语言部分的文档缺少示例,api 文档定义跟开玩笑一样。
软件使用 官方文档。
开源仓库 地址。ImHex Pattern language #
ImHex 的精髓所在。简单的理解,就是通过模式编辑器(Pattern editor),通过编程的方式将二进制文件按照内存地址解析成对应的模式(变量),并通过 Pattern Data 视图窗口将数据展示出来,可以自定义展示数据格式,颜色等,数据布局,格式分布一目了然。类比于 Java POJO中的 toString()。 参考文档
如果有main函数会直接调用。前期准备 #
准备一份分析用的二进制数据
复制如上字节数据,使用如下命令写入到 im-type 文件里面:
echo '4D 5A 90 ...' | tr -d ' ' | xxd -p -r > im-type数据类型 #
Note
数据类型有好多种,其中包括内建类型(Built-in),字节序(Endianness),字面量(Literals),枚举(Enums),数组(Arrays),指针(Pointers),位域/位段(Bitfields),结构体(Structs),共用体(Unions),Using 别名声明,模板/泛型(Templates)等。
1.内建类型 #
无符号整形,范围 \([0 , 2^{8*size}-1]\),分别使用 1B,2B,3B,4B,6B,8B,12B,16B 等字节表示
u8,u16,u24,u32,u48,u64,u96,u128。
有符号整形,范围 \([-(2^{8*size-1})\) , \((2^{8*size-1}) - 1]\),分别使用 1B,2B,3B,4B,6B,8B,12B,16B 等字节表示s8,s16,s24,s32,s48,s64,s96,s128。
浮点型,4B:float,8B:double。
特殊类型,1B:char,2B:char16,1B:bool,仅用于函数中都的str和auto。
2.字节序 #
默认所有的内建类型都使用原生的字节序,也就是电脑默认的(一般是小端序)。但是也提供可覆写的选项,通过
le,be修饰即可。3.字面量 #
一般解释为固定值的常量,有以下类型,十进制整形
42,-1337,无符号 32 bit 整形69U,有符号 32 bit 整形69,-123,十六进制整形0xDEAD,二进制整形0b00100101,八进制整形0o644,Float1.414F,Double3.14159,1.414D,Booleantrue,false,字符型'A',字符串"hello world"等。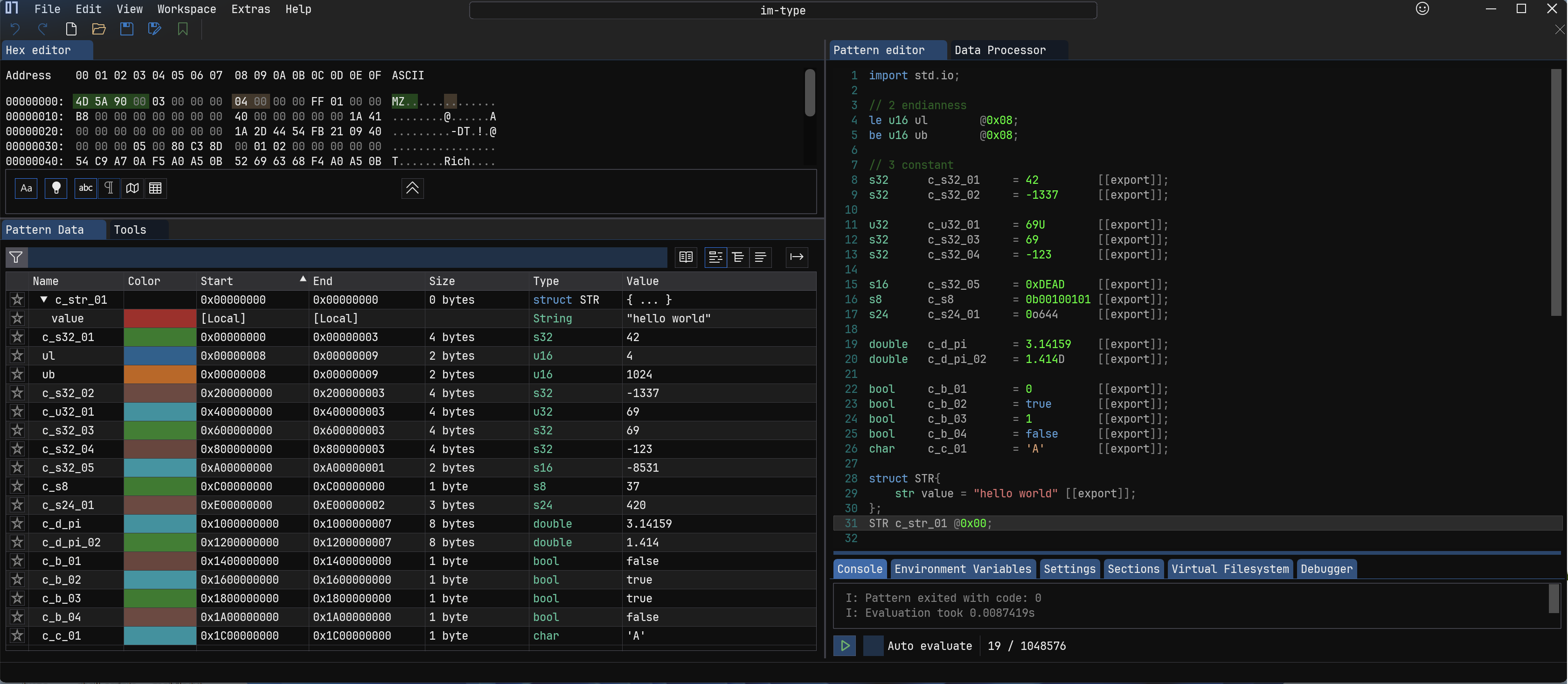
4.枚举 #
枚举类型一般是第一个的对应的值位 0x00,后面的累加 1,如果显示指定的话,这个之后从显示指定值开始加。
而且还可以枚举范围,比如用0x1A ... 0x2D中间的任何一个值来表示一个枚举类型值。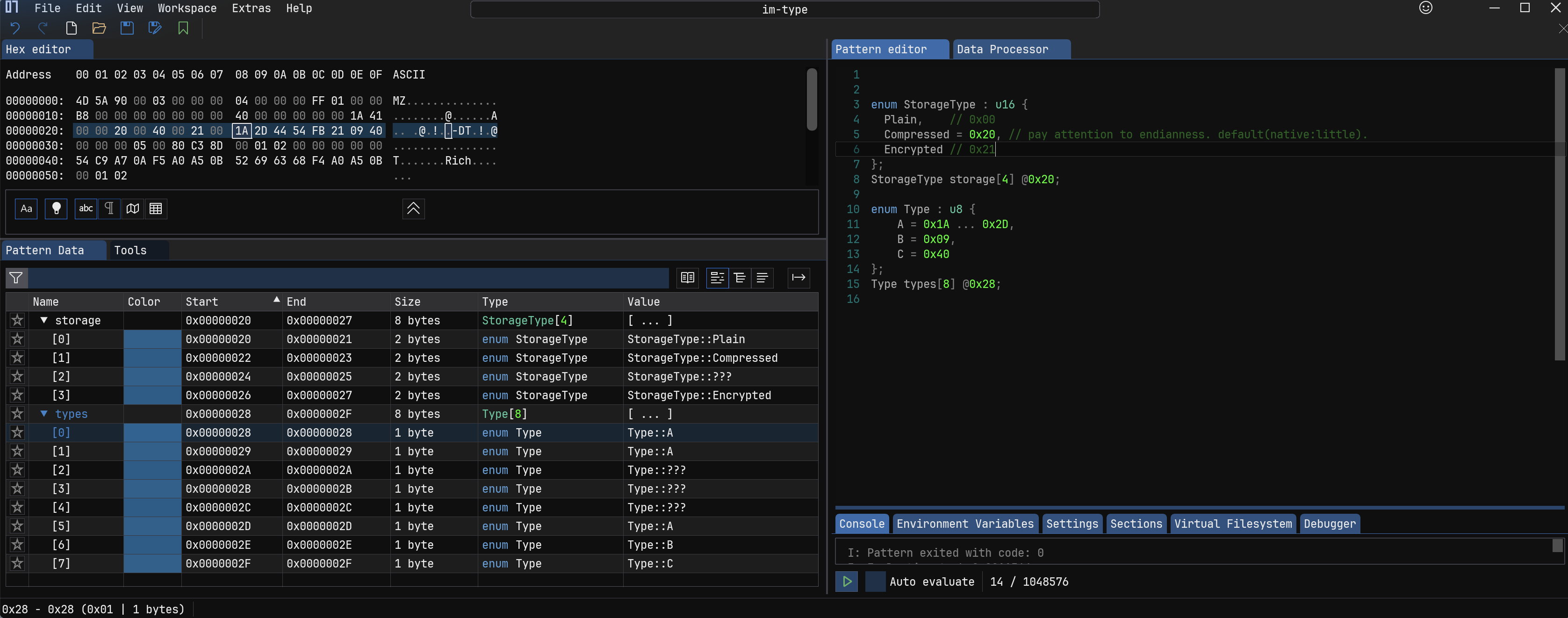
5.数组 #
有界数组:
u32 array[100] @0x00;,
无界数组:char string[] @0x53;只有碰到0x00才停止。
循环数组:u8 string[while(std::mem::read_unsigned($, 1) != 0xFF)] @ 0xFB;条件符合才停止。$表示当前位置,这个表达式的意思是从当前位置一个一个往后读,读到0xFF字节停止。
数组优化:内部是可以自动优化的,跟内存布局一致的结构体加[[static]]属性一个效果,不理解也没什么关系的。
字符数组;可以出现char,char16这样的数组,这儿应该跟宽窄字符有关系,char 一个字符一个字节,char16 一个字符使用两个字节。一般也不用具体关心解码值,使用 char 即可。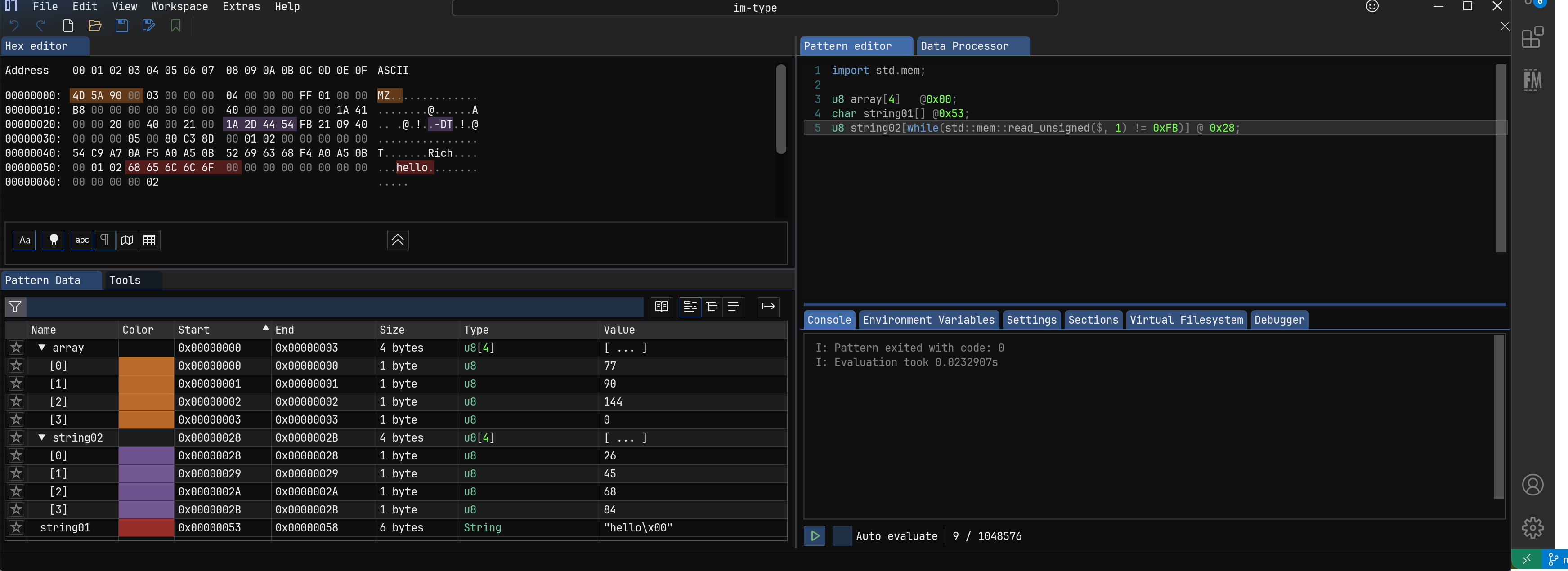
6.指针 #
普通指针形如:
u16 *pointer : u32 @0x08;表示 pointer 在 0x08 这个位置使用之后四个字节保存地址,地址对应的值指向一个占用两个字节的 u16 无符号整形值。
数组指针形如:u8 *pointerToArray[8] : s16 @0x22;表示 pointer 在 0x22 这个位置使用之后两个字节保存地址,地址对应的值指向一个数组,这个数组中的每一元素是一个字节的 u8。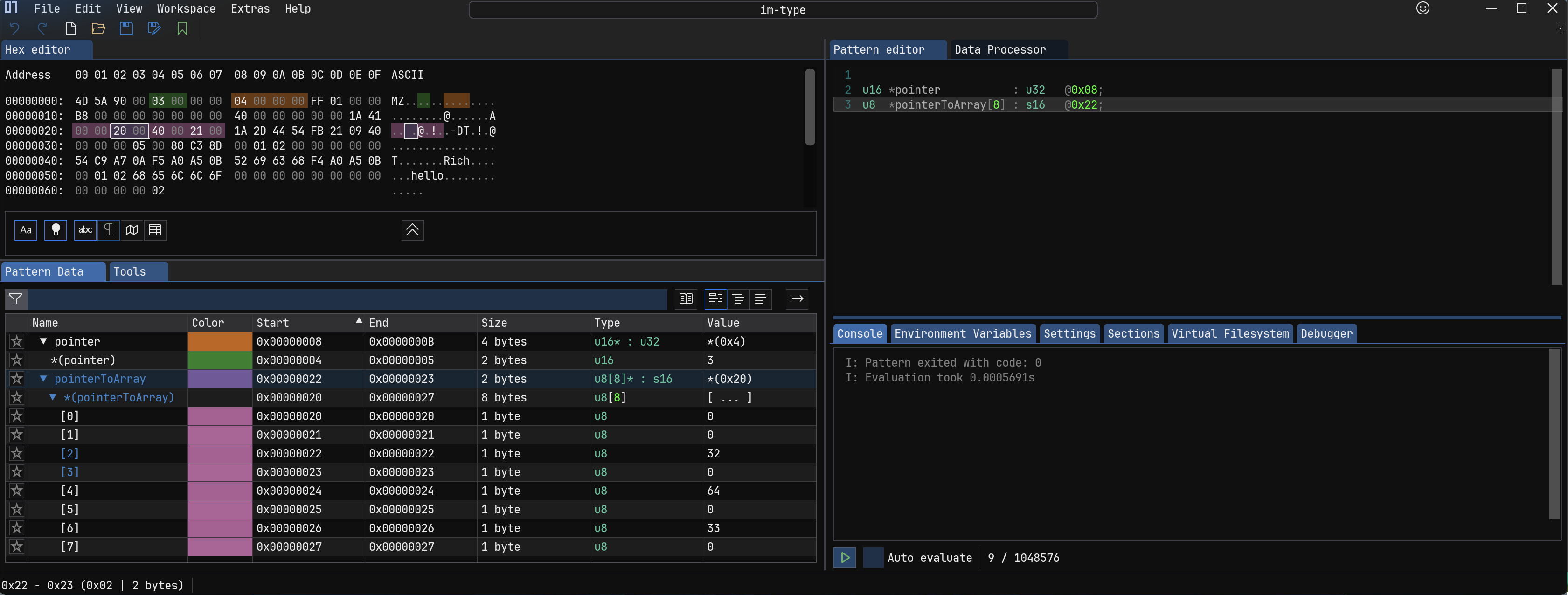
7.位段/位域 #
位域类似于结构体,但它们处理的是单独的、未对齐的位,以 bit 为单位。它们可用于解码位标志或其他使用少于8位来存储值的类型。通常来说不够一个字节,不足一个字节按一个字节处理,也就是作用范围是 8 bit 的倍数。可以在这个结构里面内嵌正常类型,也可以使用
padding关键字来填充。
单个字节从低位往高位依次读取,多个字节的时候需要注意字节序问题,具体查看代码中的注释。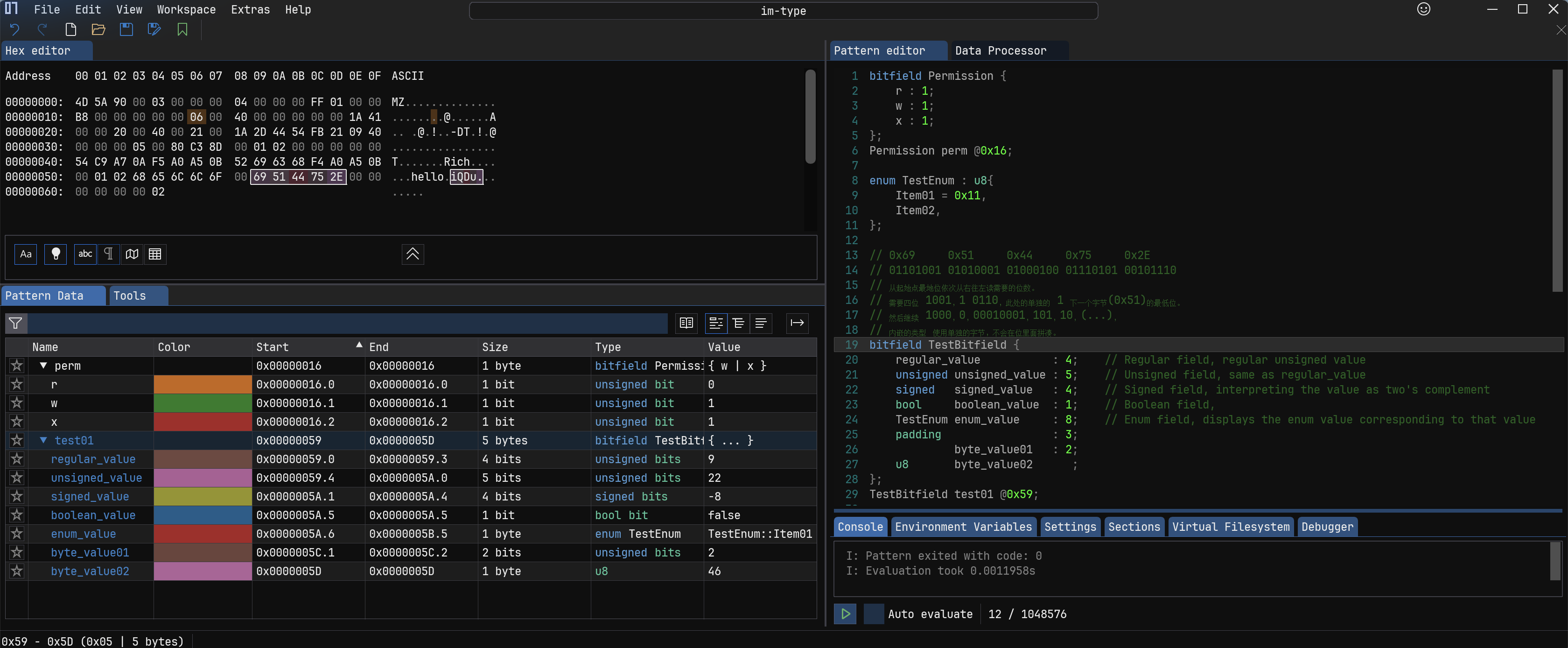
8.结构体 #
结构体表示绑定多个内建类型到一个单一的类型。
也可以使用填充padding关键字。
继承允许复制所有父类成员给子类使用。
也可以使用匿名成员,就是不用声明变量的成员,只有类型。
包括条件判断,比如根据成员 A,确定后面的结构是 B,还是 C。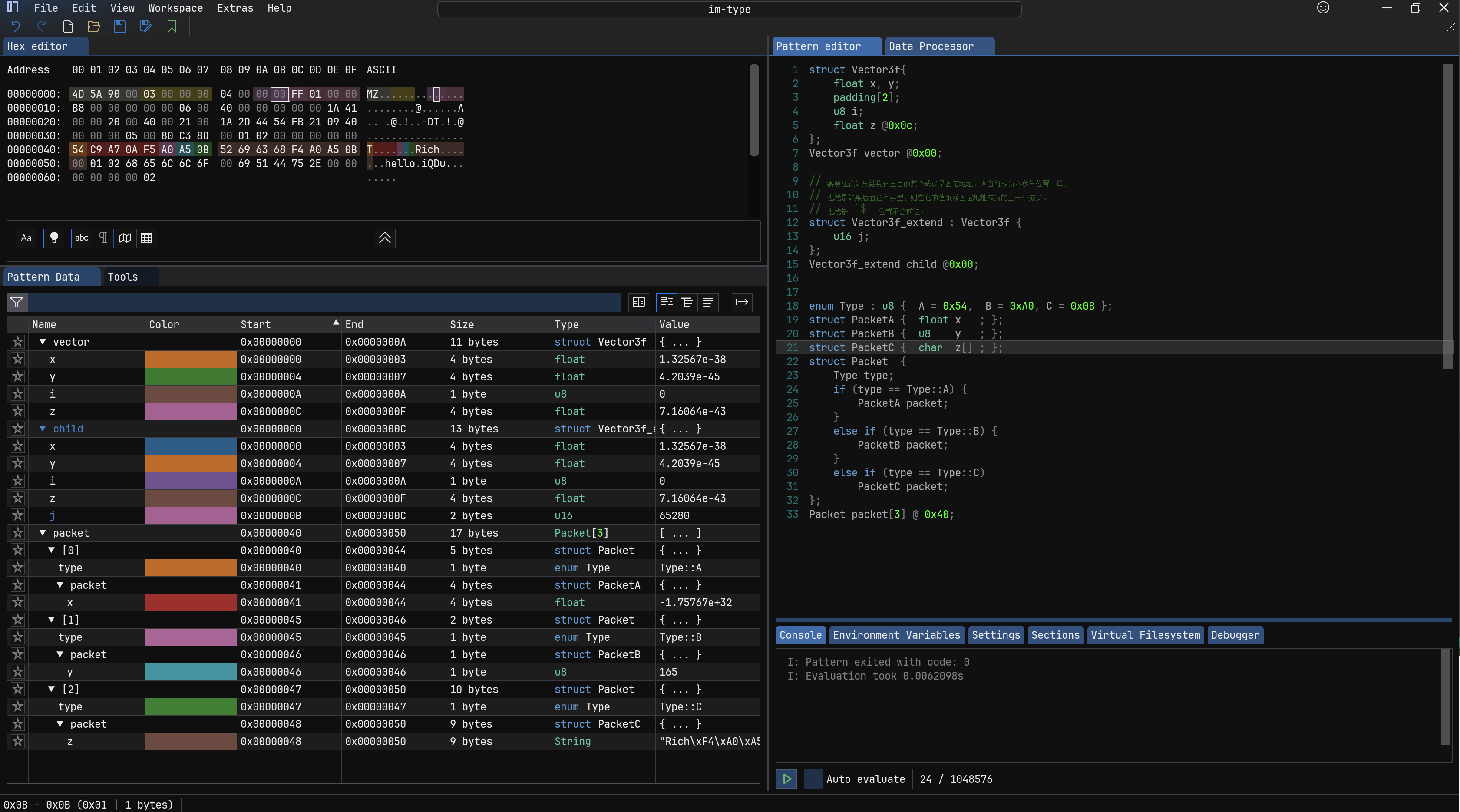
9.共用体 #
共用体和结构体类似,绑定多个类型组成一个新类型,不一样的地方在于,成员不是连续放置的,而是共享起始地址。而且以内部最大的类型占用存储空间。
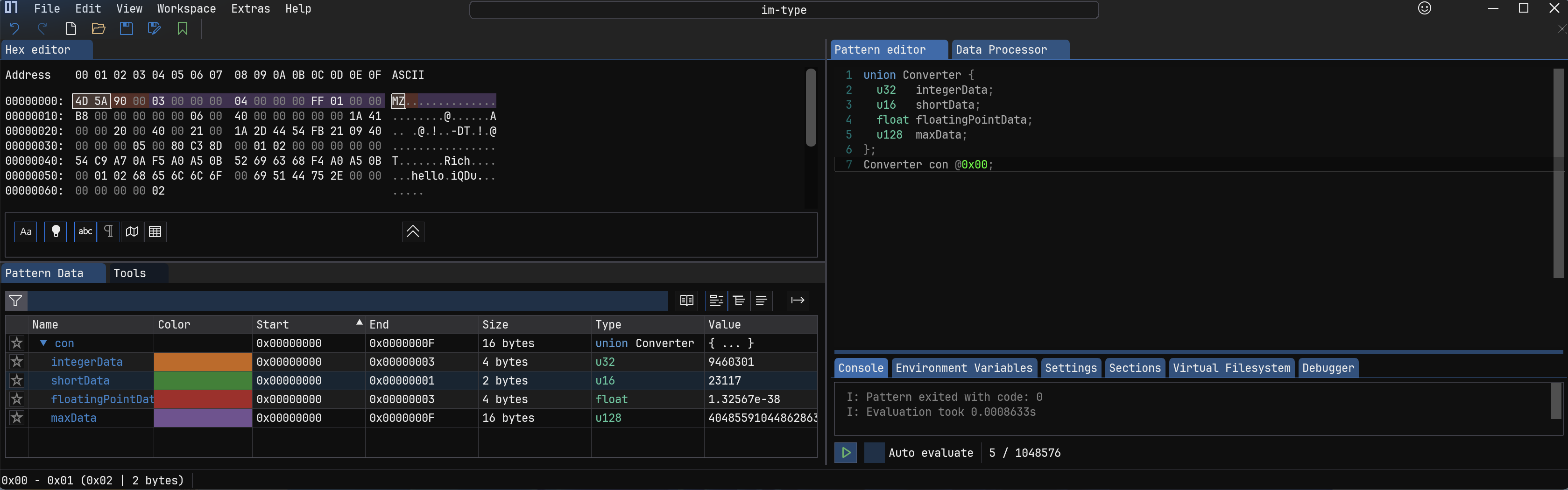
10.别名声明 #
使用
using关键字给一个已经存在类型添加一个别名,并且可以附加其他说明符,比如:using Offset = be u32;
还有一种作用就是解决两种类型之间相互引用。可以提前声明。类似:using TypeName;11.模板/泛型 #
模板可用于用占位符替换自定义类型成员类型的部分,这些占位符可在稍后实例化该类型时定义。类似于 Java 中的泛型。模板语法可以用于结构体,共用体,别名声明。
可以使用auto关键字传递非类型的模板参数,比如,数字,字符串,或变量等。
也可以在模式内部使用=来声明局部变量,用来存储临时数据。
变量放置 #
Note
变量的放置,理解成当前模式开始解析的位置可能比较容易些。就是在变量后面使用
@符跟随一个地址。上面 数据类型 中其实已经演示了,或者使用属性pointer_base动态计算地址。
另外也可以不用追加@和地址 来代表一个运行时临时保存数据的全局变量。
至于文档中提到的 Calculated pointers,意思就是 8.结构体 中使用的float z @0x0c;,用来指定模式解析的具体位置,但这些变量不影响他们所在结构体的总大小(参考结构体代码注释)。
另外在资料查找中,发现 issue:133, issue:364 跟 Calculated pointers 概念有关系。读完大致可以了解到使用pointer_base属性可以动态计算一个新的指针。但是大佬在 issue:364 中给出的 代码样例 2 有点懵逼,而且报错。貌似这种方式解决不了尺寸在指针数组之后的问题(这种情况很少碰到)。
如下使用pointer_base动态计算分割的地址(真正的地址 0x45 分别保存在 0x94 的后四位和 0x5F 的前四位),模拟 x86 GDT 中的情况: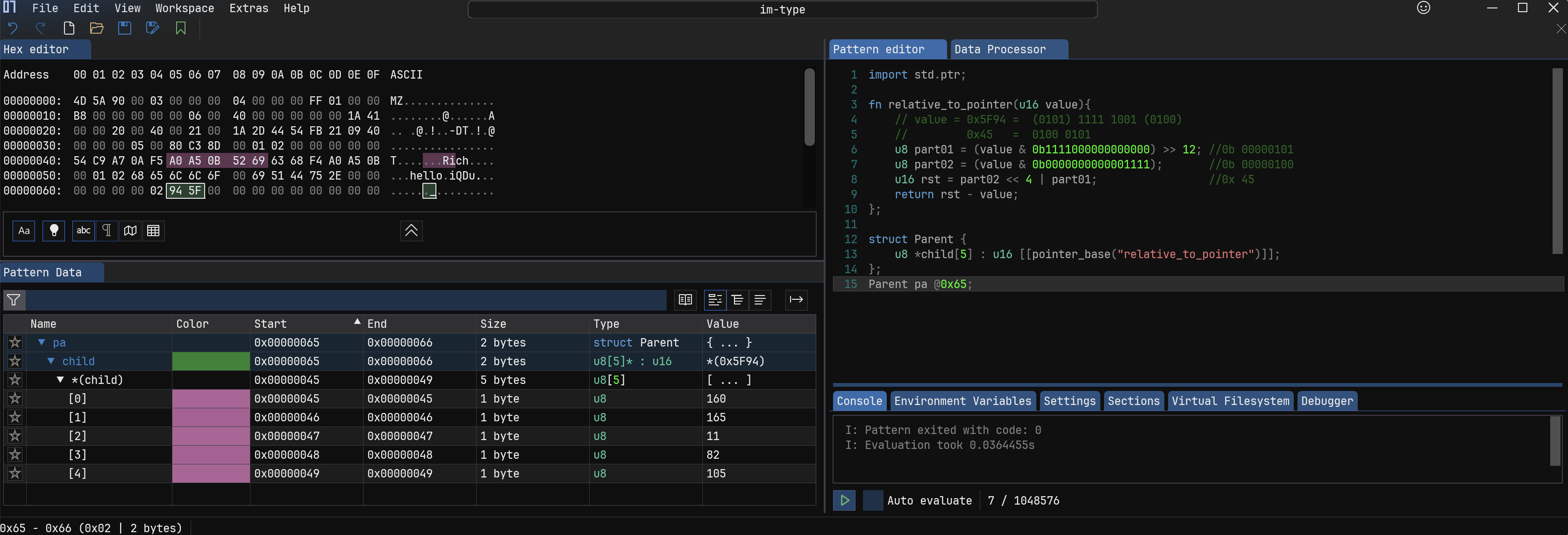
命令空间 #
表达式 #
函数 #
控制流 #
输入/输出变量 #
Note
两个内置值
in,out,可以在 Pattern editor 区域下面的 Settings tab 里面指定值,然后在程序中使用,对out的修改会同步到此处。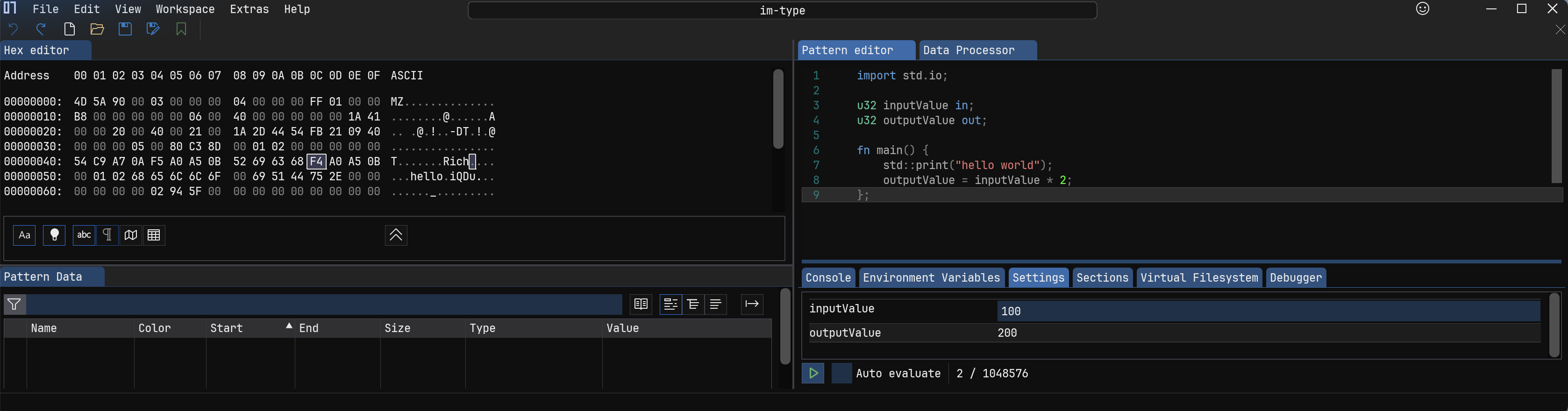
属性 #
Note
属性是一种可以追加到单独变量或者类型的特殊指令。可以理解位扩展信息,或者 Java 中的注解。可以应用多个属性到同一个变量或者类型。
变量属性 #
[[color("RRGGBB")]]:颜色属性,改变变量的显示颜色。[[name("new_name")]]:改变 Pattern data 中展示的 name,并不影响 Pattern editor 代码区域后面的引用名。[[comment("text")]]:鼠标在变量上悬浮的注释信息。[[format/format_read("formatter_function_name")]]:使用函数格式化就好了,对于返回值,一般是字符串,其他类型使用默认对应的的格式化形式。[[format_write("formatter_function_name")]]:这个一度让我摸不着头脑,苦苦搜索之后在 Modifying pattern values 发现了用法,
大致就是:在 Pattern data 区域中的 Value 字段双击可以编辑,将你输入的字符串按照给定的写函数转换成字节覆盖原本模式内容的值。[[format_entries/format_read_entries("formatter_function_name")]]:与上面的对应,不过这个只针对数组,而且覆盖所有数组实体的默认显示格式,而不仅仅是数组模式本身。[[hidden]]:不在 Pattern data 中展示,并不影响 Pattern editor 代码区域后面的引用名。[[inline]]:仅被用于数组或类结构体中。可视化地将该变量的所有成员内联到父作用域。在保持模式结构的同时,可以使显示的树结构变平,避免不必要的缩进。[[transform("transformer_function_name")]]:指定一个函数,在通过.语法(某种结构体)访问该变量之前,将执行该函数对从该变量读取的值进行预处理。[[pointer_base("pointer_base_function_name")]]:根据函数重新计算基址,并以当前位置的值为偏移量。只针对指针有效。可以参考 变量放置 里面的使用情况。
使用官方类库中的 relative_to_pointer,会报错,不知道为什么。[[no_unique_address]]:由此属性标记的变量将被放置在内存中,但不会增加当前光标的位置。跟 8.结构体 中的@使用一样,当前成员不参与位置计算,且一般与[[hidden]]配合使用。[[single_color]]:强制所有类结构体成员或数组中的每个元素都使用相同的颜色显示。
类型属性 #
Note
[[static]]:这个属性标注在自定义类型上表示当前类型的内存布局和尺寸大小完全一致,有助于优化相关的东西。比如定义了一个结构体,里面没有任何流程控制,表示每个实例对象都是一样的结构,但是有流程控制的就不一样了。比如 8.结构体 中的 Packet。[[bitfield_order(ordering, size)]]:专门对位域的属性,order表示解析顺序,size表示长度,尤其是 MostToLeast 的时候告诉它起始地址。[[sealed]]:属性用于类结构体,或者位域,它会密封实现细节,结合[[format]]只展示自身的值。[[highlight_hidden]]:和 [[hidden]] 属性一样,但是这个只是不高亮,但并没有影响变量在 Pattern view 中的展示。[[export]]:默认局部变量不会展示在输出中,并且只是存储临时值在模式内部,增加这个属性将把它变成普通变量。官方描述的”对于在输出之前进行预处理很有帮助“,不知其意。[[fixed_size(size)]]:强制一个结构体使用指定的尺寸,当小于的时候,填充到合适尺寸,大于的时候,报错。
预处理器 #
导入模块 #
注释 #
内存段 #
Note
内存段是一种可以创建附加数据缓冲区的方式,比如自定义一些数据,填充到这个段里面,然后应用到某个模式。这主要用于分析需要在运行时生成的数据,例如压缩、加密或以其他方式转换的数据。在 Pattern editor区域下面的 Sections tab 中可以选择某个段,点击后面的
view content可以查看详情。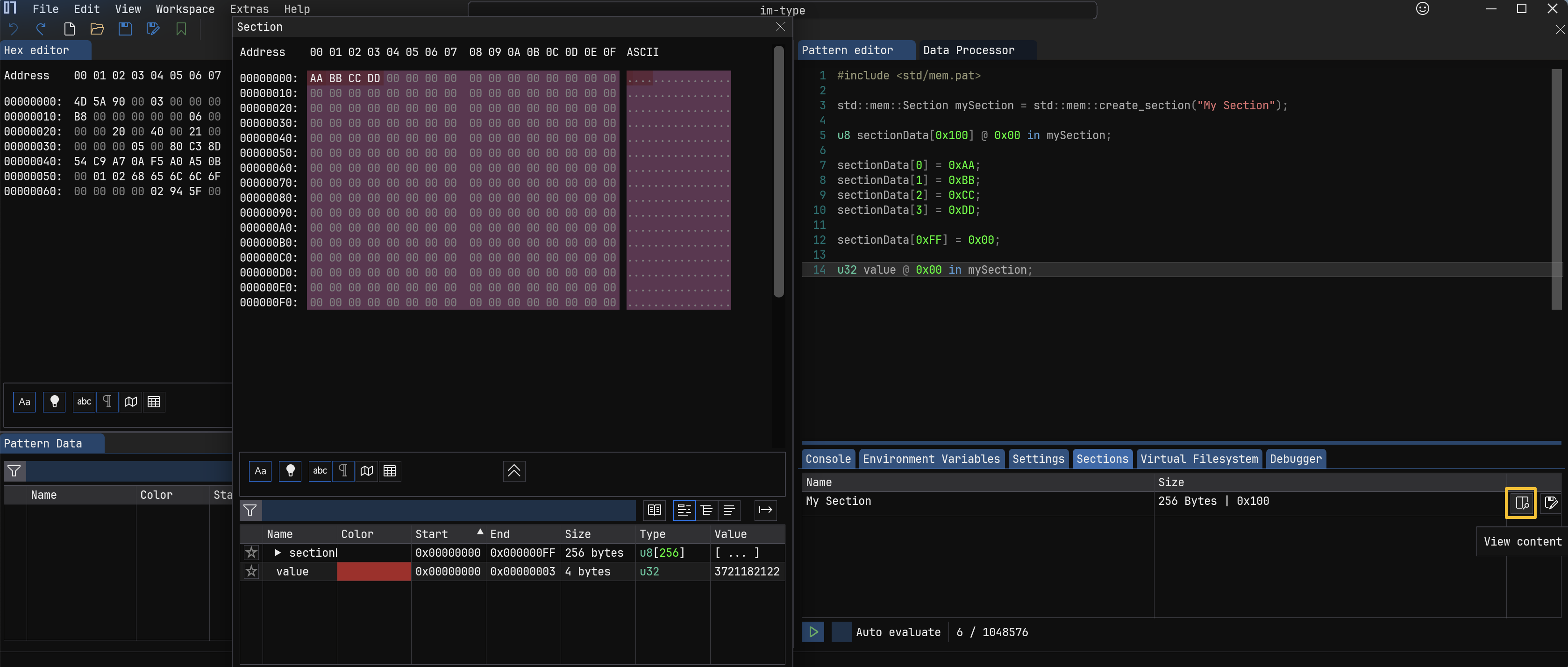
Reference #