SQUIRREL
Intro(RIME | SQUIRREL | 自定义输入法) #
Caution
因为需要输入法配置灵活度高,所以找到开源的鼠须管,基于中州韵输入法引擎的一个 macosx 端实现。 详细介绍(自序、历史、概念、项目构成、开发计划)
另外本文主要针对 【朙月拼音】 和 【小鹤双拼】 等方案进行配置,当然其他方案也可以局部参考。
贴一些使用过程中的感受:1.好用是真好用,但是学习成本是真 TM 高。如果只是想简单使用,默认配置基本够用。如果想打造成满心欢喜的神兵利器,还是需要时间滋养的。可以循序渐进。2.官方的概念多且杂,但是还又不能不看,建议有个全局了解。这样碰见其他人分享的配置文件,也能看个大概,汲取精华,去其糟粕。因为外部资料更是一搜一大堆。3.因为这东西大概在 11 年左右出来的,出道早,以至于滋生出各式各样的输入法编码,完备方案等,不懂大概运行流程及配置关系只会懵逼树下懵逼果,偷鸡的话只能祈求上天保佑好使了。下载安装 #
下载页面, macOS 鼠须管 1.0.2 pkg 安装包(属于将引擎中州韵代码作为 git 子模块,编译成动态链接库供鼠须管使用)
macOS 编译指南
鼠鬚管 Wiki
重新部署: 参考/Library/Input\ Methods/Squirrel.app/Contents/MacOS/Squirrel --reloadcontrol + option + .
配置 #
配置文件位置 #
Warning
应运程序的安装位置:
/Library/Input\ Methods/Squirrel.app/Contents
程序附带的共享配置:/Library/Input\ Methods/Squirrel.app/Contents/SharedSupport/
用户自定义覆写目录:~/Library/Rime/
配置文件目录及文件分布参考 (RimeWithSchemata / Rime 中的數據文件分佈及作用)
配置文件的 YAML 升级语法参考 (Configuration / Rime 配置文件)
对于定制选项可参考 (CustomizationGuide / 定製指南)外观-Squirrel(鼠须管) #
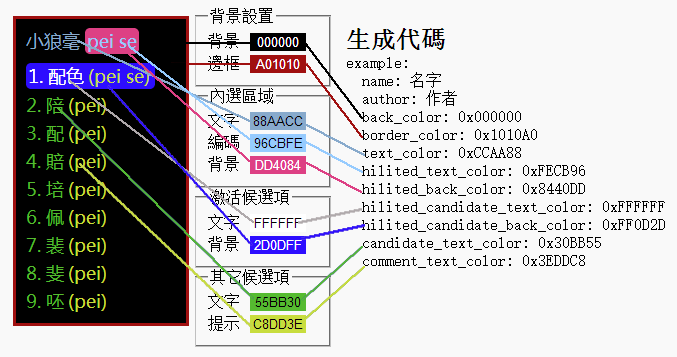
图片引用自 官方的示例图,小狼毫和鼠须管外观配置基本一致。如需设置,则可以参考 主題設計助手 或者 润笔 - Rime 设置小助手
引擎-Librime(中州韵) #
文档和样例
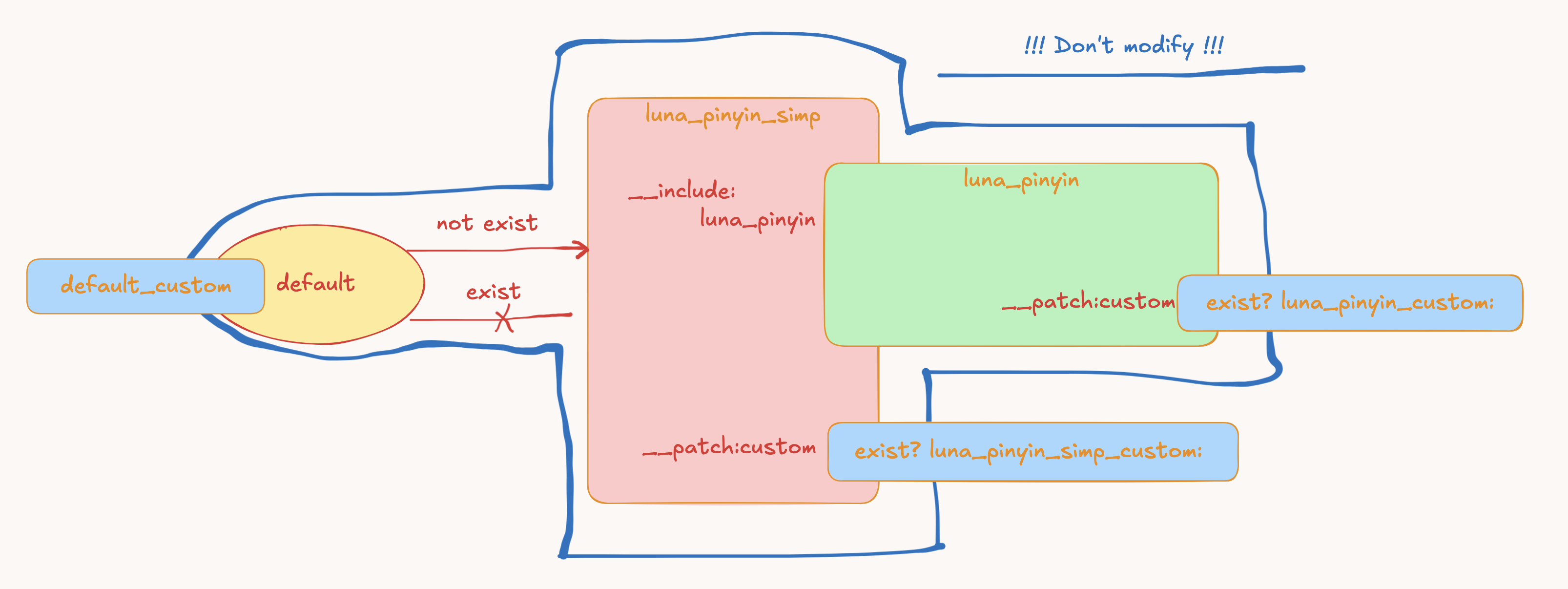
1).: 配置文档: 01-RimeWithSchemata 02-雪齋的文檔 03-CustomizationGuide2).: 参考样例: 01-rime-luna-pinyin 02-rime-prelude 03-綜合演練 / hello根据配置文档自己画的配置关系图如下:
Caution
因为官方不建议修改的 Shared 文件的原因,所以有些属性就得通过 custom 文件进行覆盖或者补丁。
朙月拼音【自定义及解释】 #
外观相关参数 #
可以将输入法展示区块分为三部分:inline(目标区),preedit(编辑区)[可消失],candidate(候选区)[不消失]
inline_preedit__:编辑区与目标区行内显示(简单理解为编辑区覆盖目标区)inline_candidate:候选区与目标区行内显示(简单理解为候选区覆盖目标区)
同时覆盖的话,编辑区消失,候选区上位,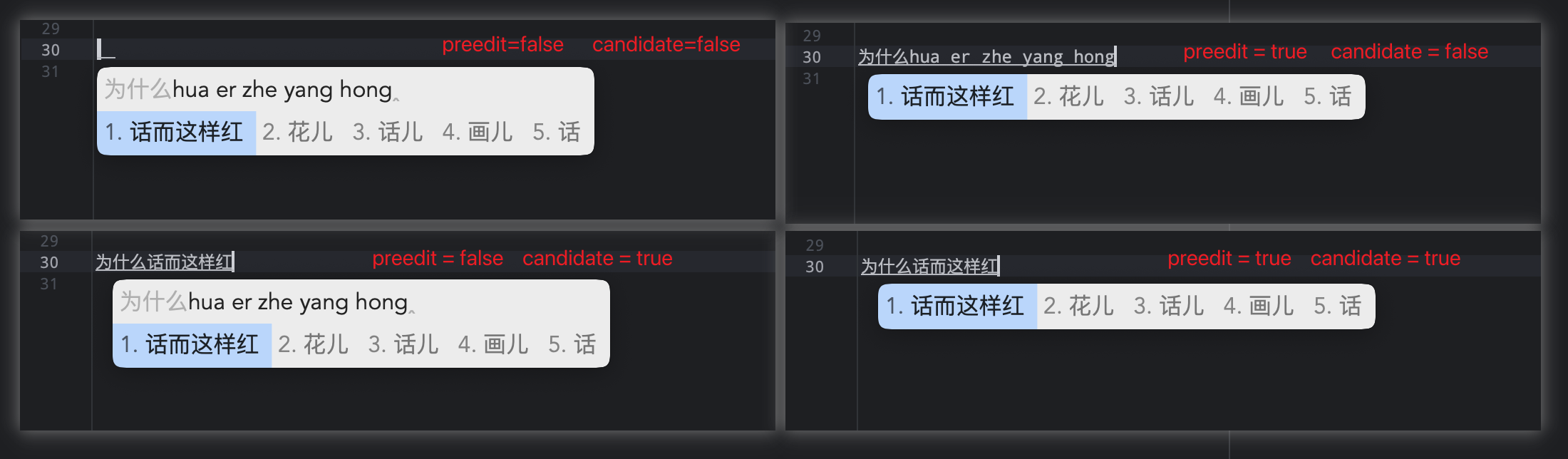
分隔符修改 #
修改拼写分隔符:
luna_pinyin.custom.yaml。由原来的delimiter: " '"到delimiter: "'"speller/delimiter:引用(RimeWithSchemata / 【三】最高武藝)中的注释:隔音符號用「’」;第一位的空白用來自動插入到音節邊界處。
翻译过来就是可以手动通过第二位对拼音进行分割,比如西安这个的拼音xi'an,就可以手动打',其余自动分割的用第一个符号。
改完后delimiter: "'"的一二位因为一样,所以使用一个就可以了。
翻页配置 #
修改翻页为-|=: 预定义。
在位置default.custom.yaml,key_binder: 增加两个 bindings (结果没生效){ when: paging, accept: minus, send: Page_Up}{ when: has_menu, accept: equal, send: Page_Down}
大意了,原来预置的key_bindings.yaml里买就有相关快捷键的定义,但是自己手贱,又重新在default.custom.yaml里面重新定义了,并且没有绑定相关键位,发现不生效,以为原来的预置的键位没有绑定上去。其实应该是在 custom 文件里面进行追加或者修改的,不是直接定义(会覆盖)。
例如:右边default.custom.yaml代码中追加和修改示例。修改插入记号(CARET) #
修改 caret(插入记号):符号
‸,此处的符号引用自 UI Improvements / 10。查看 librime 引擎中相关代码,发现在 此处 使用了😝|模拟了插入记号,所以感觉应该是在每个客户端(squirrel|weasel)中去自自己实现的。然后转到 squirrel,在 此处 SquirrelInputController.swift 发现相关代码,其中 caretPos 就是指定了位置,但是并没有看出来是怎么使用的,比如是直接将插入符号追加到编辑区 还是 在后续调用中根据位置直接设置的。swift 代码不太好看,无从下手了,所以没有解决。在此处仅做个记录。
更新上述错误表述:后面查看代码的时候发现在 librime 引擎处有 kCaretSymbol 定义,而且在下面一行处有用户可配置的选项soft_cursor,大概熟悉代码后发现这只是一个开关(false|true),用来控制是否显示插入符号的开关,通过 debug 验证后发现可行。于是添加如下图括起来的类似配置,在本地进行测试,发现在 Squirrel 端并不生效。于是查看 squirrel 端代码,发现有 这样的判断,进而对soft_cursor进行了覆写,所以没生效。但是根据它的判断条件也可以进行验证,一般对于浏览器,都是进行强制内联(inline)的。所以在浏览器地址栏输入就不会出现插入符号了。
接着,为了实现修改插入记号的初始想法,就必须修改引擎代码然后重新编译出动态链接库,替换 squirrel 自己编译出来的。步骤如下:1).: 修改 kCaretSymbol 定义 中 38 行代码为:static const string kCaretSymbol("\xe2\x86\x9e");,\xe2\x86\x9e就是你想替换的任何 UTF-8 符号的十六进制编码。比如我此处的就是↞。2).: 此处使用 clion + camke 的方式编译出动态链接库/path/librime/cmake-build-release/lib/librime.1.11.2.dylib3).: 进入 squirrel 输入法目录:cd /Library/Input Methods/Squirrel.app/Contents/Frameworks4).: 备份 squirrel 自带(或它附带编译出来)的:sudo mv librime.1.dylib librime.1.dylib.bak5).: 使用刚才编译出的进行替换:sudo cp /path/librime/cmake-build-release/lib/librime.1.11.2.dylib librime.1.dylib6).: 重启输入法进行验证:/Library/Input\ Methods/Squirrel.app/Contents/MacOS/Squirrel --quit,过一会自己就启动了。
如果需要此次编译出来 macOS 端的动态链接库librime.1.11.2.dylib, 点击下载。
需要注意的是:a).: 这次编译出来的 Release 版本大小为3.4M,原来的为7.0M,不知道什么区别,仅供测试。(后来发现跟插件有关系,比如 lua)b).: 浏览器中编辑框中最后的那个竖线|是闪动的光标,正好闪动的时候截的图。

添加LUA脚本 #
lua脚本使用,直接输入日期之类的
使用方法:a).: 在用户配置目录~/Library/Rime/新建文件rime.lua,里面的内容 参考 hchunhui/librime-lua/wikib).: 在luna_pinyin.custom.yaml中添加engine/translators/@before 0/: lua_translator@date_translator, 启用 lua 日期翻译器。效果如下左 gif。
但是这样的话,自己编译的librime.1.11.2.dylib里面没有启用插件,需要将插件编译进去,编译过程如下:1).: 目前 rime 生态体系支持的插件有 这些 plugins2).: 如果想要安装某个插件,比如hchunhui/librime-lua,进入到源码目录 librime ,在终端执行./install-plugins.sh hchunhui/librime-lua。会将插件仓库下载到当前目录的plugins中。
其他插件类似,但是hchunhui/librime-lua,这个插件的 CMakeLists.txt 第五行有点问题,我本地是有 lua-5.4.6 的,但是它没检测到,将lua54改成lua5.4即可通过重建 cmake 工程。3).: 将 clion 切换到 Release profile, 重新 build 即可重新生成cmake-build-release/lib/librime.1.11.2.dylib。4).: 如上 修改插入记号CARET 的操作,复制替换重启一气呵成。效果如下右 gif。
如果需要此次编译出来 macOS 端的动态链接库2ed-librime.1.11.2.dylib, 点击下载。

添加词库 #
添加搜狗 网络, 计算机 等相关词库。并使用在线工具 词库转换器,将 scel 文件转换成 txt,比如:网络流行新词【官方推荐】.txt 、计算机词汇大全【官方推荐】.txt
秉承不修改 Shared 目录文件的原则,通过给luna_pinyin.schema.yaml打补丁,修改translator/dictionary 的值。
具体操作如下:1).: 将 Shared 目录 /Library/Input\ Methods/Squirrel.app/Contents/SharedSupport/ 中的luna_pinyin.dict.yaml复制一份到用户目录 ~/Library/Rime/ ,并改名为luna_pinyin_compact.dict.yaml。2).: 编辑luna_pinyin_compact.dict.yaml,在 use_preset_vocabulary 一行后面添加import_tables: [ sougou_pinyin_network, sougou_pinyin_computer ]3).: 新建文件sougou_pinyin_network.dict.yaml,先写入如下模板头,剩下的通过命令将 txt 内容追加到后面即可。计算机同样的方式。4).: 导入命令:cat /path/网络流行新词【官方推荐】.txt >> sougou_pinyin_network.dict.yaml5).: 将原来luna_pinyin.schema.yaml中定义的translator/dictionary: luna_pinyin通过打补丁的方式替换,这样明月拼音相关方案中的词典都会替换。
补丁方法:在luna_pinyin.custom.yaml添加内容补丁:translator/dictionary: luna_pinyin_compact
卸载词库也很简单,只需要将补丁行translator/dictionary: luna_pinyin_compact注释即可,这样原来的就会起作用。
词库去重部分暂时没处理。另外还有 这样: issues/214 的问题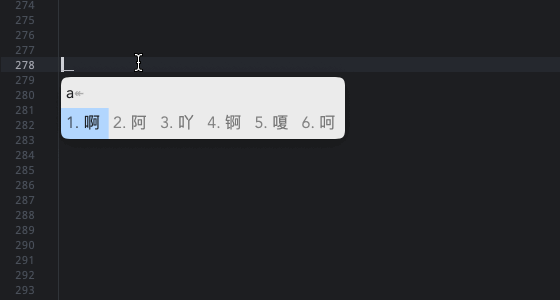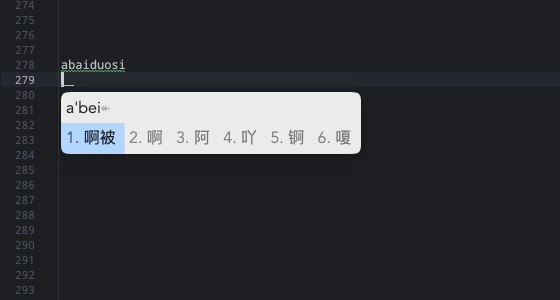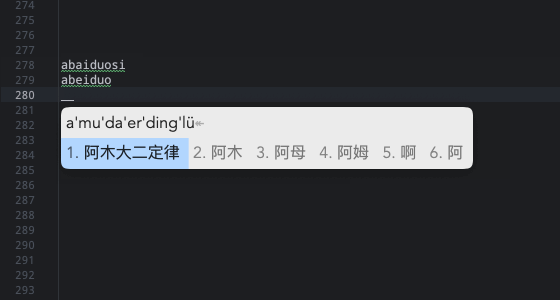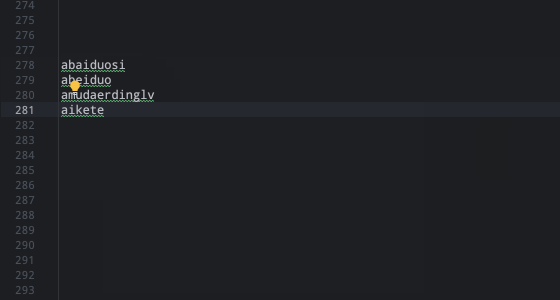

中英混输 #
要想在中文模式下输入英文单词,有一种办法就是将输入的编码 通过自定义的 table 类型的英文翻译器进行转换,只需要进行相关的配置就行。
具体操作如下:1).: 先生成字典配置en_dict.dict.yaml如右所示,网上下载这两个码表en.dict.yaml(主表)、en_ext.dict.yaml(扩展表)。
重命名en.dict.yaml==>en_primary.dict.yaml2).: 配置自定义文件luna_pinyin.custom.yaml,新增英文翻译器(table_translator@english),主要配置如右。
还有一个默认的主翻译器,稍后要进行调频,所以一起配置了。3).: 进行调频,其实就是给两个翻译器配置中的initial_quality进行赋值,参数可以 参考:优化 Rime 英文输入体验/权重设定4).: 重新部署,如果没问题,日志没报错,那就是没问题了,直接输入体验就行。
但是我的日志报错:Error loading table for dictionary 'en_dict'.5).: 解决方式就是暂时将我们的en_dict配置给主翻译器,让生成 *.bin 词典数据后,再换回来。5.1).互换右边第 4 和 17 行。5.2).重新部署一次,让生成 bin 文件,如果成功的话会在用户目录下 build 文件夹生成 **en_dict.***等文件。5.3).互换右边第 17 和 4 行。5.4).再次重新部署就没问题了。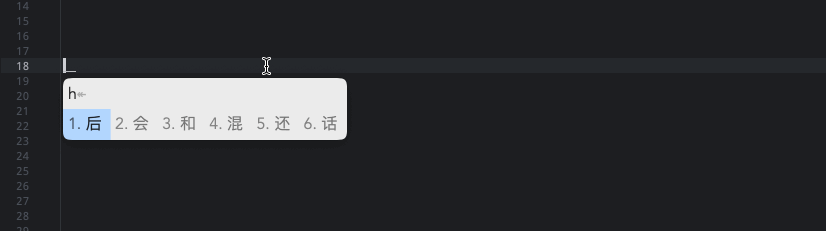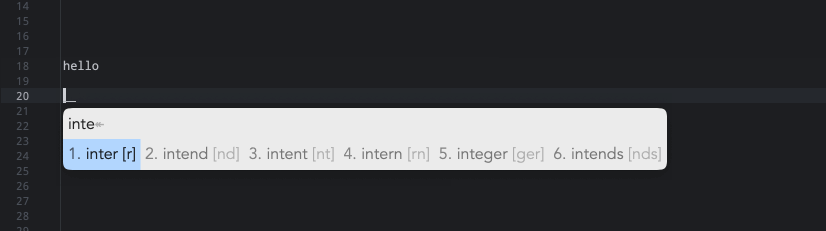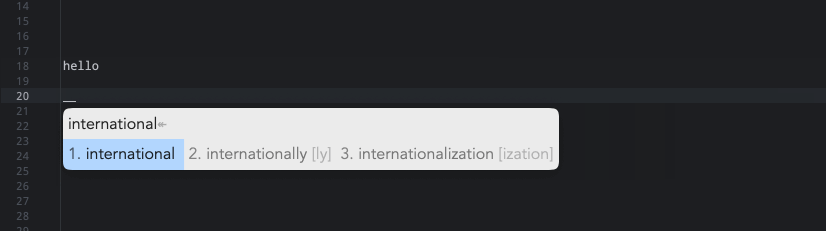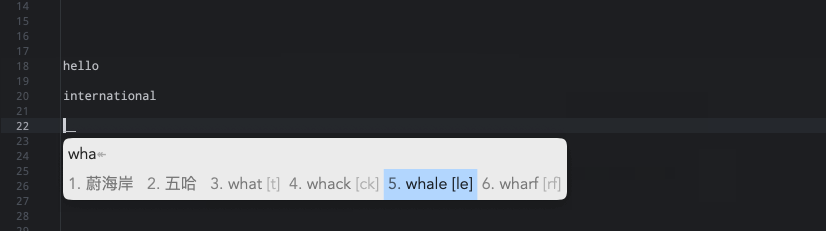
中英自动添加空格 #
想要实现在中西文中间自动加入空格的这种功能,官方在引擎部分可能不打算实现了,参考 issues:24。不过我们可以借助 Lua 脚本辅助解决一下,虽然不是那么完美,但对于我来说,够了。
对于实现部分,照猫画虎,参照 issues:238 实现思路,以及 aux_code.lua 语法中通知部分。最后实现的 append_space.lua 如下折叠的 Lua 脚本。
大致思路是:通过 通知功能 将上一次上屏的内容类型记录在 rime 的某个环境变量中,供后续判断使用。然后针对当前输入所带出来的每个候选项进行过滤,逐个匹配看是否要添加空格(也就是修改候选项)。比如输入完你好上屏之后,此时给 prior_commit_type 环境变量赋值 1 表示上一段是中文,紧接着下次输入hello候选项里面有英文单词,短语之类的话,就替换为前置空格的候选项。相应的,如果输入其他符号,则将 变量置为 0,表示不需要转换。Caution
1:因为状态判断是存在引擎环境变量中,没有很好的时机去重置,所以如果不是相邻的地方也会存在影响。
比如第一行输入你好了,然后在第二行输入hello也会出现空格(vscode 会自己忽略,挺好,😆)。2:目前只处理候选项,不会对 preedit 进行干预。
Lua 脚本
反查配置 #
在查资料的过程中,发现有其他配置文件中比较喜欢反查,于是查了一下 【反查】的意思:大概就是使用其他方案来解释当前的输入,比如当前要是使用朙月拼音输入法的话,输入特定的反查前缀触发后续匹配,比如要用笔画字典中的值(㐀 shhsh),假设前缀为
Ub,则输入码为Ubshhsh的话,就可以打出来【㐀】字了。
处理流程:1.先是 matcher 分段器结合配合 recognizer 中 patterns 所定义的正则对应的值为后续的输入打上标签。2.然后此类标签段由 reverse_lookup_translator 或者reverse_lookup_translator@xxx 翻译器根据指定的字典进行查询翻译,返回候选词在候选框。
注意事项1.配置反查可以有其他实现方案。2.目前配置了两种反查,一种是笔画(横竖撇捺折),另一种是拆字(三木为森)。默认的配置给了 stroke(笔画),新增一个reverse_lookup_translator@radical_reverse_lookup用于 拆字。3.且都已大写字母U开头,笔画是Ub,拆字是Uc。所以需要在 speller/alphabet 中将大写字母加进去,不然输入大写字母可能就流产了,另一个好处是可以翻译大写字母开头的单词。4.避免默认的大写匹配,感觉这种没卵用,就覆盖了。recognizer/patterns/uppercase: ""5.下方演示中的 Ub 因为有配置preedit_format: [ "xlit/hspnz/一丨丿丶乙/"]这样的转换,所以输入的 shhsh 变为了 【丨一 一 丨 一】。
参考资料:
https://github.com/mirtlecn/rime-radical-pinyin
https://www.mintimate.cc/zh/demo/reverseWords.html
可以参考的完整补丁配置
辅助码解决方案 #
辅助码这种技术一般是跟随着双拼出现的,根据出现背景了解到其实是为了解决同音字候选项较多,不能精准定位,需要多次翻页才可以找到的情况。比如在小鹤双拼中
vi这个编码可能有好几百个候选词,如何精准定位到某一个就需要辅助码了。比如 【小鹤音形】 就是一种辅助码的形式,采用 音码 + 形码 的方式精准定位。
所以可以简单理解辅助码为过滤码。知道大概怎么回事儿后,就可以发现其实也可以用于其他各种编码方案,包括我们使用的 朙月拼音。
目前知道的在 rime 中发挥作用的辅助码有如下两种形式:
第一个是混合编码: 如 rime-flypy-zrmfast 中所采用的方式
其实就是将编码已音码]形码的方式硬编码在字典文件 flypy_zrmfast.dict.yaml 中。例如:智 vi[uo,后面的形码采用的方式是小鹤音形的。( 形码速查网址)
当用户输入vi的时候,会显示 zhi 音相关词汇,继续输入[uo,会直接匹配到字典表中的智。
第二个是单独编码(目前所采用的形式): 如 rime-lua-aux-code,使用单独的辅助码字典和 lua 脚本即可完成过滤,而且可以根据情况触发,比较灵活。如下运作过程:1.正常输入过程不会涉及到辅助码,lua 脚本拦截后只是简单传递,并不会对候选项做其他额外的处理(包括过滤和添加提示码等)。2.当输入触发符号;(可配置)的时候,并且继续输入的时候就会发挥作用,将;之后的输入当形码,在单独的辅助码字典中查找并过滤。3.将过滤结果已候选词的形式展示,供用户选择。
注意事项:
跟 反查配置 中的 speller/alphabet 一样,需要对上屏字母进行排除,不然流产。
当前将第二种形式集成到使用的两个方案中,下图展示了分别在 朙月拼音 和 小鹤双拼 中如何根据形码快速定位智。(因为之前输入过,排在前面了,不影响效果,换成其他的也无妨)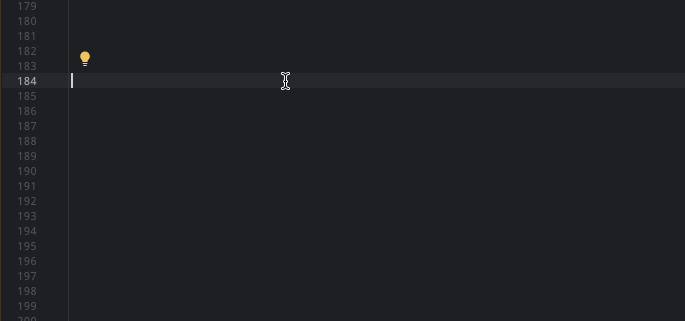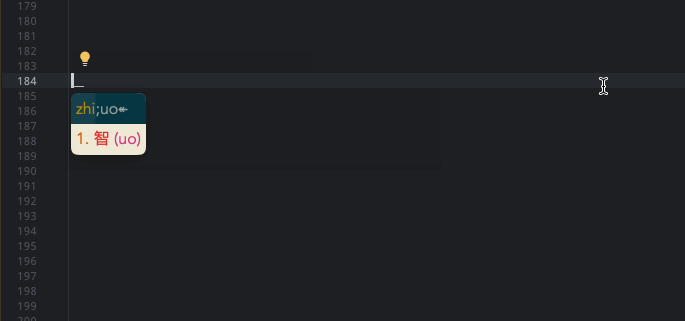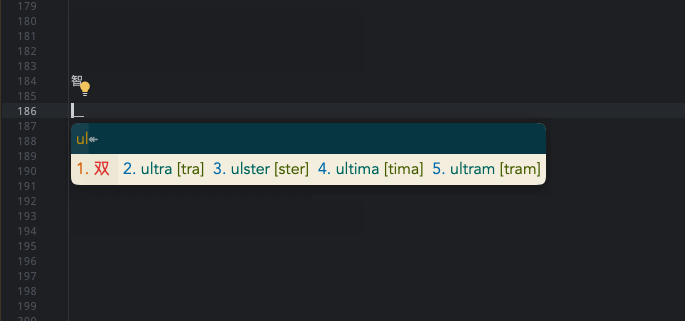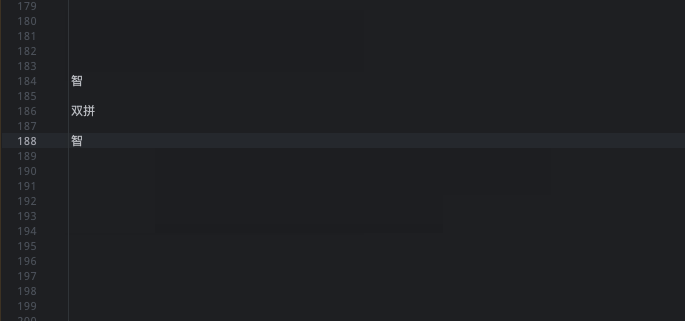
可以参考的完整补丁配置
微信表情快捷输入 #
翻找表情比较麻烦,还不知道什么意思,所以利用输入法配置一下。
采用自定义符号的形式, 参考:Rime 自定義短語文件樣例
需要注意:这个是微信功能支持,输入表情格式的文字会转换为对应的表情,和输入法没关系。此处的输入法只是为了将输入liu转化为[666],touxiao转化为[偷笑]等。
具体操作如下:1).: 因为默认配置里面已经写好相关引用了,所以只需要在用户目录下新建custom_phrase.txt文件,将微信表情相关的符号写入到里面就可以了。符号定义如下:
如果是百度输入法,则可以 参考:baidu输入法个性短语导入
微信表情自定义符号
配置符号直接上屏(GRAVE) #
因为写 markdown 较多的缘故,所以经常用到
`反引号,用来注释重要的内容,中英切换比较费事,所以想不管中英模式,敲`直接上屏。
如果直接通过补丁的方式覆盖的话, 对于加了commit的值会报错copy on write failed; incompatible node type: commit参考/issues/504, 所以得直接复制一份共享目录下面的 symbols.yaml 文件到用户目录,并改名为 symbols_updated.yaml。 采用迂回的方式对luna_pinyin.schema.yaml中的 punctuator 直接覆盖。这样既绕过了 commit 的问题,也不用修改原来的 symbols.yaml 文件。
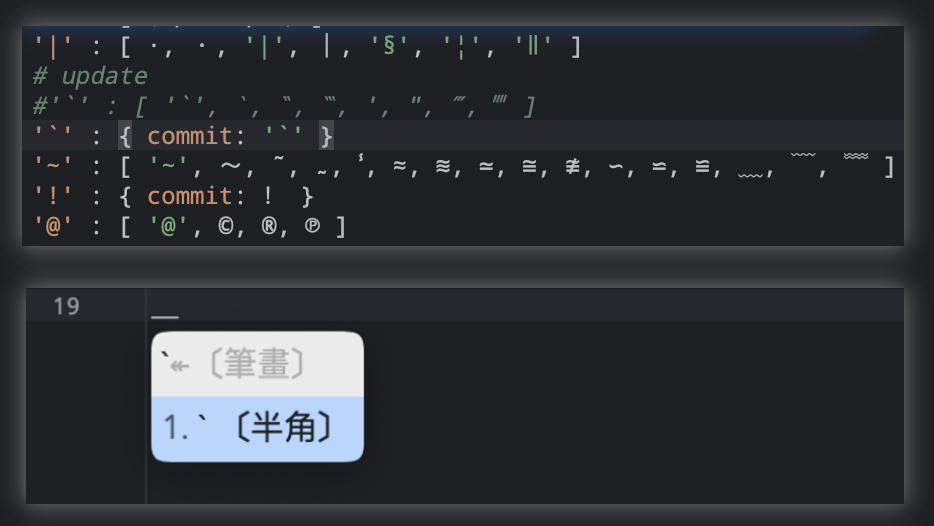
具体操作如下:1).: 修改 symbols_updated.yaml 中的 half_shape 如下图第一个片段。
正常来说应该已经生效了,但是配置文件中还有其他影响的部分,比如 反查前缀等。所以还需要进行 2,3两步。2).: 补丁覆写:reverse_lookup/prefix: ")",目前不知道这个反查是什么东西,影响不大。 【反查释义】3).: 补丁覆写:recognizer/patterns/reverse_lookup: "R:[a-z]*'?$"。4).: 重新部署查看效果。(gif中第一次输入后出现两个`,是 clion 的自动补全效果,后面就正常了)
配置回车直接上屏 #
默认的回车操作是上屏
编辑区域的内容,源码可以 参考: editor.cc#L189-L218,相关配置解释可以 参考 Rime_description.md#八其它/第5个
使回车和空格一样的操作按照如下配置就行。
具体操作如下:1).: 在luna_pinyin.custom.yaml中加入补丁:editor/bindings/Return: confirm。取消CTRL触发中西文切换 #
平常使用 vim 的时候进行模式切换、退出会用到
ctrl + [。因为刚开始的错误配置,很容易触发 中西文切换,所以用下方补丁调整一下。小鹤双拼 #
Rime引擎 #
版本:[2024/09/29]:https://github.com/rime/librime/tree/aaaaaec344c22c1b3b8059190a00e4c532a2ab54
源码处理参考 #
Tip
engine中的所有模块组合 gears_module.ccengine中对于按键的处理流程 ConcreteEngine::ProcessKeyengine中处理器processor中 fluid_editor/fluency_editor 和 express_editor 的处理 异同编译与调试 #
Note
由于需要查看 yaml 文件生成后到底是什么样的,以及配置了为什么没有生效等问题。所以将源代码拉取下来,进行分析,结合日志打印出的信息以及 AIGC 等问答,最后修改 librime 输入法引擎部分代码,实现测试,验证等效果。
上述部分可以使用更方便的方式查看,在后续学习中发现的。其实在用户目录下的 ~/Library/Rime/build 目录就包含完整(补丁后)的方案 yaml 以及编译好的词典文件。
修改的commit为: aaaaaec3
编译参考文档: Rime with Mac
文件变更: feat: add yaml dump to temp dir for test and verify.
各种bin文件解析 #
使用 java 对项目中使用到的各种 bin 文件进行解析,参考 代码
用户习惯数据探索 #
其他 #
Caution
1).: 在计算机科学和编程中,grave通常指的是“重音符”或“倒尖号”,在键盘上通常位于数字 1 键的左边,形状像一个倾斜的撇号,有时也被称为反引号`。 — 来自阿里通义2).:space理解为空格,这个算是基本常识了、但是backspace一度懵逼,后来一查,发现是退格键。😝
Reference #
- https://rime.im
- https://github.com/rime/home/wiki
- https://github.com/rime/squirrel/wiki
- https://github.com/rime/home/wiki/SpellingAlgebra [运算子]
- https://github.com/ssnhd/rime
- Where can I find the documentation on the key “speller/initials”?
- https://www.hawu.me/others/2666
- 有哪些好用且开源的输入法?
- RIME v0.16.1 小狼毫輸入法(支援Win, macOS, Linux)
- 一位匠人的中州韵——专访Rime输入法作者佛振(图灵访谈)